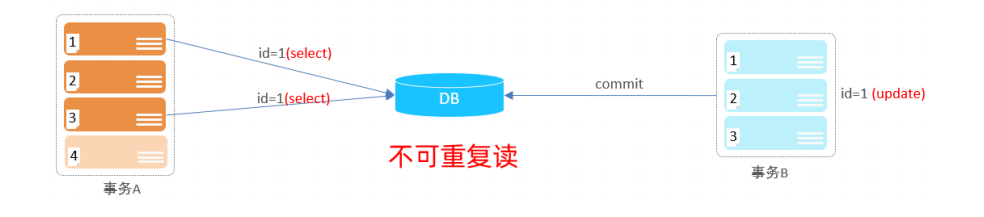
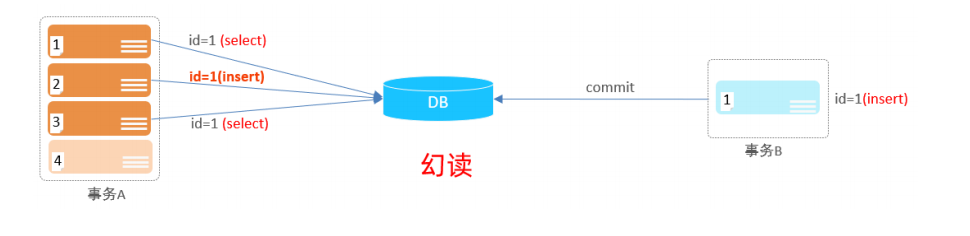
-- 条件查询 -- 1. 查询年龄等于88的员工信息 select*from emp where age=88; -- 2. 查询年龄小于20的员工信息 select*from emp where age<20; -- 3.查询年龄小于等于20的员工信息 select*from emp where age<=20; -- 4. 查询没有身份证号的员工信息 select*from emp where idcard isnull; -- 5. 查询由身份证号的员工的信息 select*from emp where idcard isnotnull ; -- 6. 查询年龄不等于88的员工信息 select*from emp where age!=88; select*from emp where age <>88; -- 7.查询年龄在15(包含)岁到20岁(包含)之间的员工信息 select*from emp where age between15and20; -- between 跟最小值 and跟最大值 select*from emp where age>=15and age<=20; -- 8.查询性别为女 且年龄小于20 的员工信息 select*from emp where gender='女'and age<20; -- '&&' is deprecated and will be removed in a future release. Please use AND instead select*from emp where (gender='女'&& age<20); -- 9. 查询年龄等于18或 20 或 40的员工信息 select*from emp where age in(18,20,40); select*from emp where age=18OR age=40OR age=20; -- '|| as a synonym for OR' is deprecated and will be removed in a future release. Please use OR instead select*from emp where age=18|| age=20|| age=40;
select*from emp where name like'__'; -- 注意是 下划线 -- 11. 查询身份证最后以为是X的员工信息 select*from emp where idcard like'%X'; select*from emp where idcard like'____________________X';-- 17个_ 占位符
2.6.3 聚合函数
1). 介绍
将一列数据作为一个整体,进行纵向计算 。
2). 常见的聚合函数
函数
功能
count
统计数量
max
最大值
min
最大值
avg
平均值
sum
求和
3).语法
1
SELECT 聚合函数(字段列表) FROM 表名 ;
注意 : NULL值是不参与所有聚合函数运算的。
1 2 3 4 5 6 7 8 9 10 11 12
-- 聚合函数 -- 1.统计该企业员工数量 selectcount(*) from emp; -- 由于聚合函数不统计null,所以统计总数常用 * selectcount(id) as'企业员工总数'from emp; -- 2.统计该企业员工的平均年龄 selectavg(age) from emp; -- 3.统计该企业的最大年龄 selectmax(age) as'最大年龄'from emp; -- 4. 统计该企业员工的最小年龄 selectmin(age) from emp; -- 5.统计西安地区员工的年龄之和 selectsum(age) from emp where workaddress='西安';
2.6.4 分组查询
1) 语法
1
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUPBY 分组字段名 [ HAVING 分组后过滤条件 ];
-- 流程控制函数 -- if select if(false,'OK','ERROR'); -- if null select ifnull('ok','default'); select ifnull('','default'); select ifnull(null,'default');
-- case when then else end -- 需求:查询emp表的员工姓名和工作地址(北京/上海---> 一线城市,其他---> 二线城市) select name, case workaddress when'北京'then'一线城市'when'上海'then'一线城市'else'二线城市'endas'工作地址' from emp;
-- 统计各个学员的成绩,展示的规则如下: -- >= 85 展示优秀 -- >= 60 展示及格 -- 否则,展示不及格 createtable score( id int comment 'ID', name varchar(20) comment '姓名', math int comment '数学', english int comment '英语', chinese int comment '语文' ) comment '学员成绩表'; insertinto score(id, name, math, english, chinese) VALUES (1, 'Tom', 67, 88, 95), (2, 'Rose' , 23, 66, 90),(3, 'Jack', 56, 98, 76); select*from score;
select id, name, casewhen math>=85then'优秀'when math >60then'及格'else'不及格'endas'数学', casewhen english>=85then'优秀'when score.english >60then'及格'else'不及格'endas'英语', casewhen chinese>=85then'优秀'when score.chinese >60then'及格'else'不及格'endas'语文' from score;
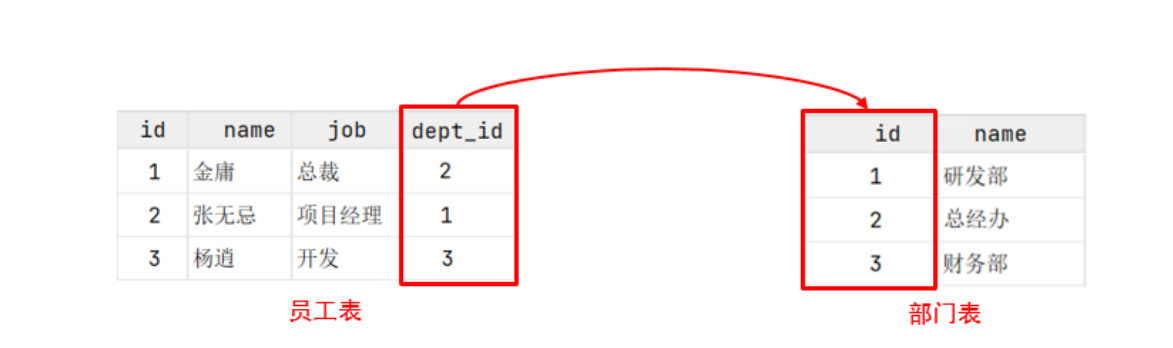
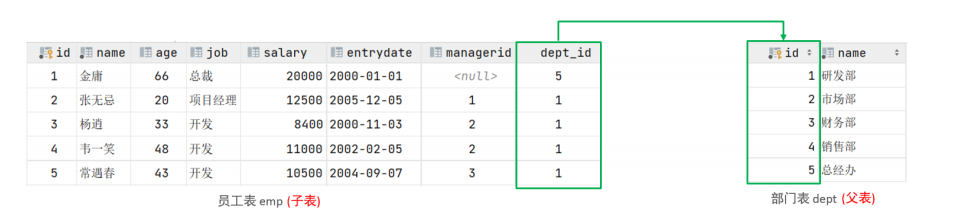
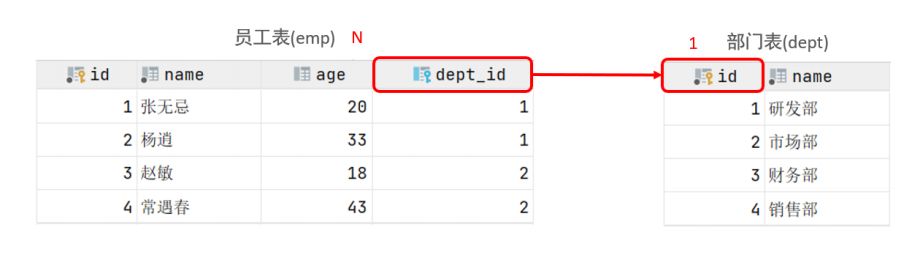
-- 准备数据 createtable dept( id int auto_increment comment 'ID'primary key, name varchar(50) notnull comment '部门名称' )comment '部门表';
createtable emp( id int auto_increment comment 'ID'primary key, name varchar(50) notnull comment '姓名', age int comment '年龄', job varchar(20) comment '职位', salary int comment '薪资', entrydate date comment '入职时间', managerid int comment '直属领导ID', dept_id int comment '部门ID' )comment '员工表';
-- 外连接演示 -- 1. 查询emp表的所有数据, 和对应的部门信息(左外连接) -- 表结构 :emp,dept -- 连接条件:emp.dept_id=dept.id select e.*,d.name from emp e leftouterjoin dept d on d.id = e.dept_id; -- outer 可以省略 select e.*,d.name from emp e leftjoin dept d on d.id = e.dept_id; -- 2. 查询dept表的所有数据, 和对应的员工信息(右外连接) select d.*,e.name from dept d rightjoin emp e on d.id = e.dept_id;
-- 自连接 -- 1. 查询员工 及其 所属领导的名字 -- 表结构: emp select a.name,b.name from emp a,emp b where a.managerid=b.id; -- 2. 查询所有员工 emp 及其领导的名字 emp , 如果员工没有领导, 也需要查询出来 -- 表结构: emp a , emp b select a.name,b.name from emp a leftjoin emp b on a.managerid=b.id;
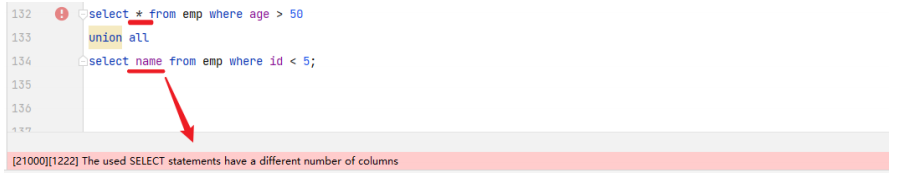
SELECT 字段列表 FROM 表A ... UNION [ ALL ] SELECT 字段列表 FROM 表B ....;
对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
union all 会将全部的数据直接合并在一起,union 会对合并之后的数据去重。
1 2 3 4 5 6 7 8 9 10
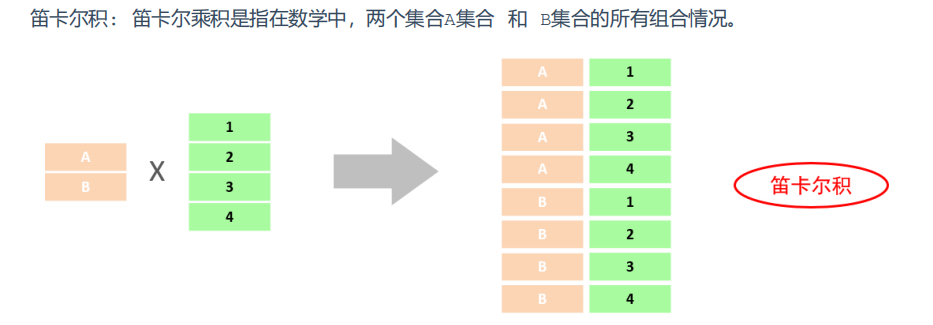
-- union all , union -- 1. 将薪资低于 5000 的员工 , 和 年龄大于 50 岁的员工全部查询出来. -- union all 直接合并 select*from emp where salary<5000 unionall select*from emp where age>50; -- union 会去重 select*from emp where salary<5000 union select*from emp where age>50;
根据子查询结果不同,分为:
A. 标量子查询(子查询结果为单个值)
B. 列子查询(子查询结果为一列)
C. 行子查询(子查询结果为一行)
D. 表子查询(子查询结果为多行多列)
根据子查询位置,分为:
A. WHERE之后
B. FROM之后
C. SELECT之后
5.6.2 标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用的操作符:= <> > >= < ≤
1 2 3 4 5 6 7 8 9 10 11 12
-- 标量子查询 -- 1.查询“销售部”所有员工的信息 -- a.查询销售部的ID select id from dept where name='销售部'; -- b.根据销售部的ID查询员工信息 select*from emp where dept_id=4;
select*from emp where dept_id=(select id from dept where dept.name='销售部');
-- 2. 查询在 "方东白" 入职之后的员工信息 select*from emp where entrydate>(select entrydate from emp where name='方东白'); id from dept where name='研发部'));
5.6.3 列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:IN 、NOT IN 、 ANY 、SOME 、 ALL
操作符
描述
IN
在指定的集合范围之内,多选一
NOT IN
不在指定的集合范围之内
ANY
子查询返回列表中,有任意一个满足即可
SOME
与ANY等同,使用SOME的地方都可以使用ANY
ALL
子查询返回列表的所有值都必须满足
1 2 3 4 5 6 7 8 9 10 11 12 13
-- 列子查询 -- 1.查询市场部和销售部的 所有员工信息 -- 查询销售部和市场部的部门ID -- 根据部门ID,查询员工信息 select*from emp where dept_id in(select id from dept where dept.name in ('市场部','销售部')); -- 2. 查询比财务部所有人员工工资都高的员工信息 -- --a.查询所有财务部人员工资 -- select salary from emp where dept_id=(select id from dept where name='财务部'); select*from emp where salary >all(select salary from emp where dept_id=(select id from dept where name='销售部')); -- select max(salary) from emp where dept_id=(select id from dept where dept.name='财务部' ); select*from emp where salary>(selectmax(salary) from emp where dept_id=(select id from dept where dept.name='销售部' )); -- 3. 查询比研发部其中任意一人工资高的员工信息 select*from emp where salary >any(select salary from emp where dept_id=(select id from dept where name='研发部'));
5.6.4 行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
1 2 3 4 5
-- 行子查询 -- 1.查询与张无忌的薪资及直属领导相同的员工信息 select salary,managerid from emp where name='张无忌'; -- select *from emp where (salary=(select salary from emp where name='张无忌')) and managerid=(select managerid from emp where name='张无忌'); select*from emp where (salary,managerid)=(select salary,managerid from emp where name='张无忌');
5.6.5 表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:IN
1 2 3 4 5 6 7 8 9 10
-- 表子查询 -- 查询与 鹿杖客,宋远桥的职位和薪资相同的员工的信息 select job,salary from emp where name in('鹿杖客','宋远桥'); select*from emp where (job,salary) in(select job,salary from emp where name in('鹿杖客','宋远桥'));
-- 2.查询入职日期是 '2006-01-01'之后的员工信息,及部门信息 -- a. 入职日期是 "2006-01-01" 之后的员工信息 select*from emp where entrydate>'2006-01-01'; -- b. 查询这部分员工, 对应的部门信息; select e.*,d.*from (select*from emp where entrydate>'2006-01-01') e leftjoin dept d on d.id=e.dept_id;
-- 1.查询员工的姓名、年龄、职位、部门信息(隐式内连接) select e.name,e.age,e.job,d.name from emp e,dept d where e.dept_id=d.id; -- 2. 查询年龄小于30岁的员工的姓名、年龄、职位、部门信息(显式内连接) -- select e.name,e.age,e.job,d.name from (select * from emp where age<30) e join dept d on d.id=e.dept_id; select e.name,e.age,e.job,d.name from emp e join dept d on d.id=e.dept_id where age<30; -- 3. 查询拥有员工的部门ID、部门名称 selectdistinct d.id,d.name from emp e,dept d where e.dept_id=d.id; -- 4.查询所有年龄大于40岁的员工,及其归属的部门的名称;如果员工没有分配部门,也要展示出来 select*from emp e leftjoin dept d on d.id = e.dept_id where e.age>40; -- 5.查询所有员工薪资等级 -- 连接条件 emp.salary>=salgrade.losal and emp.salary>=salgrade.histal select e.*,s.grade '薪资等级'from emp e ,salgrade s where e.salary>=s.losal and e.salary<=s.hisal; select e.*,s.grade '薪资等级'from emp e ,salgrade s where e.salary between s.losal and s.hisal; -- 6.查询研发部所有员工的信息及工资等级 -- 表:emp,salgrade,dept -- 连接条件:emp.salary between salgrade.losal and salgrade.histal emp.dept_id=dept_id -- 查询条件: dept.name='研发部' select e.*, s.grade '薪资等级' from emp e, salgrade s, dept d where e.salary between s.losal and s.hisal and (e.dept_id = d.id) and d.name ='研发部';
-- 7.查询研发部员工的平均工资 selectavg(salary) '研发部平均薪资'from emp e,dept d where e.dept_id=d.id and d.name='研发部'; -- 8.查询工资比灭绝高的员工信息 select*from emp e where salary>(select salary from emp e2 where e2.name='灭绝'); -- 9.查询比平均工资高的员工信息 select*from emp where salary>(selectavg(salary) from emp); -- 10.查询低于本部门平均工资的员工信息 -- a. 查询指定部门平均薪资 1 selectavg(e1.salary) from emp e1 where e1.dept_id =1; selectavg(e1.salary) from emp e1 where e1.dept_id =2; -- b. 查询低于本部门平均工资的员工信息 select*from emp e2 where salary<(selectavg(e1.salary) from emp e1 where e1.dept_id = e2.dept_id); select*,(selectavg(e1.salary) from emp e1 where e1.dept_id = e2.dept_id) '平均薪资'from emp e2 where salary<(selectavg(e1.salary) from emp e1 where e1.dept_id = e2.dept_id);
-- 11. 查询所有的部门信息, 并统计部门的员工人数 selectcount(*) from emp where dept_id=1;
select d.id,d.name,(selectcount(*) from emp where dept_id=d.id) '人数'from dept d;
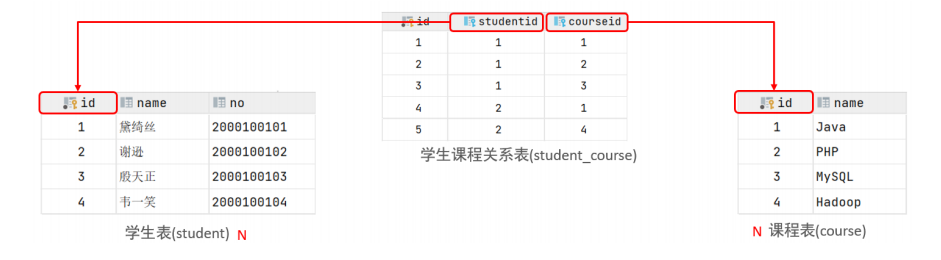
-- 12. 查询所有学生的选课情况, 展示出学生名称, 学号, 课程名称 -- 表: student , course , student_course -- 连接条件: student.id = student_course.studentid , course.id = student_course.courseid select s.name,s.no,c.name from student s,student_course sc,course c where s.id=sc.courseid and sc.courseid=c.id;