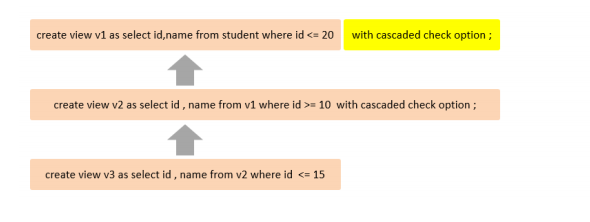
-- 将传入的 200分制的分数,进行换算,换算成百分制 , 然后返回分数 ---> inout createprocedure p5(inout score double) begin set score:=score*0.5; end; set@score=198; call p5(@score); select@score;
4.2.6 case
1). 介绍
case结构及作用,和我们在基础篇中所讲解的流程控制函数很类似。有两种语法格式:
语法1:
1 2 3 4 5 6 7
-- 含义: 当case_value的值为 when_value1时,执行statement_list1,当值为 when_value2时, 执行statement_list2, 否则就执行 statement_list CASE case_value WHEN when_value1 THEN statement_list1 [ WHEN when_value2 THEN statement_list2] ... [ ELSE statement_list ] ENDCASE;
语法2:
1 2 3 4 5 6 7
-- 含义: 当条件search_condition1成立时,执行statement_list1,当条件search_condition2成 立时,执行statement_list2, 否则就执行 statement_list CASE WHEN search_condition1 THEN statement_list1 [WHEN search_condition2 THEN statement_list2] ... [ELSE statement_list] ENDCASE;
-- 先判定条件,如果条件为true,则执行逻辑,否则,不执行逻辑 WHILE 条件 DO SQL逻辑... END WHILE;
2). 案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14
-- while 计算从1累加到n的值,n为传入的参数值。
-- A. 定义局部变量, 记录累加之后的值; -- B. 每循环一次, 就会对n进行减1 , 如果n减到0, 则退出循环 createprocedure p7(in n int) begin declare total intdefault0; while n>0 do set total:=total+n; set n:=n-1; end while; select total; end; call p7(10);
4.2.8 repeat
1).介绍
repeat是有条件的循环控制语句, 当满足until声明的条件的时候,则退出循环 。具体语法为:
1 2 3 4 5
-- 先执行一次逻辑,然后判定UNTIL条件是否满足,如果满足,则退出。如果不满足,则继续下一次循环 REPEAT SQL逻辑... UNTIL 条件 END REPEAT;
2). 案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
-- repeat 计算从1累加到n的值,n为传入的参数值。 -- A. 定义局部变量, 记录累加之后的值; -- B. 每循环一次, 就会对n进行-1 , 如果n减到0, 则退出循环 createprocedure p8(in n int) begin declare total intdefault0; repeat set total:=total+n; set n:=n-1; until n<=0 end repeat; select total; end; call p8(10); call p8(100);
-- loop 计算从1累加到n的值,n为传入的参数值。 -- A. 定义局部变量, 记录累加之后的值; -- B. 每循环一次, 就会对n进行-1 , 如果n减到0, 则退出循环 ----> leave xx createprocedure p9(in n int) begin declare totoal intdefault0; sum:loop if(n<=0) then leave sum; end if; set totoal:=totoal+n; set n:=n-1; end loop sum; select totoal; end; call p9(10);
-- loop 计算从1到n之间的偶数累加的值,n为传入的参数值。 -- A. 定义局部变量, 记录累加之后的值; -- B. 每循环一次, 就会对n进行-1 , 如果n减到0, 则退出循环 ----> leave xx -- C. 如果当次累加的数据是奇数, 则直接进入下一次循环. --------> iterate xx createprocedure p10(in n int) begin declare totoal intdefault0; sum:loop if(n<=0) then leave sum; end if; if(mod(n,2)<>1) then set n:=n-1; iterate sum; end if;
set totoal:=totoal+n; set n:=n-1; end loop sum; select totoal; end; call p10(100);
-- 逻辑: -- A. 声明游标, 存储查询结果集 -- B. 准备: 创建表结构 -- C. 开启游标 -- D. 获取游标中的记录 -- E. 插入数据到新表中 -- F. 关闭游标
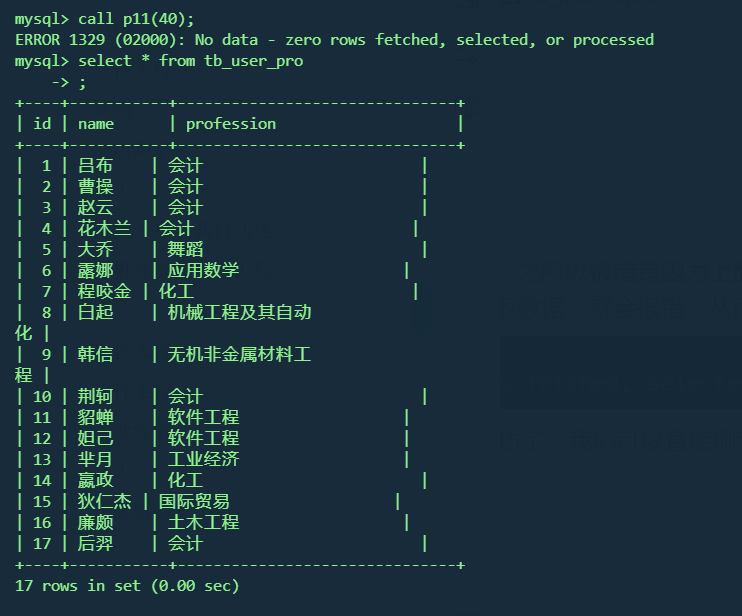
createprocedure p11(in uage int) begin -- 先声明变量在声明游标 declare u_name varchar(100); declare upro varchar(100); declare u_cursor cursorforselect name,profession from tb_user where age<=uage; droptable if exists tb_user_pro; createtable if notexists tb_user_pro( id intprimary key auto_increment, name varchar(100), profession varchar(100) ); open u_cursor; while true do fetch u_cursor into u_name,upro; insertinto tb_user_pro values (null,u_name,upro); end while; close u_cursor;
-- 逻辑: -- A. 声明游标, 存储查询结果集 -- B. 准备: 创建表结构 -- C. 开启游标 -- D. 获取游标中的记录 -- E. 插入数据到新表中 -- F. 关闭游标 createprocedure p11(in uage int) begin declare uname varchar(100); declare upro varchar(100); declare u_cursor cursorforselect name,profession from tb_user where age <= uage; -- 声明条件处理程序 : 当SQL语句执行抛出的状态码为02000时,将关闭游标u_cursor,并退出 declare exit handler forSQLSTATE'02000'close u_cursor; droptable if exists tb_user_pro; createtable if notexists tb_user_pro( id intprimary key auto_increment, name varchar(100), profession varchar(100) ); open u_cursor; while true do fetch u_cursor into uname,upro; insertinto tb_user_pro values (null, uname, upro); end while; close u_cursor; end; call p11(30);
createprocedure p12(in uage int) begin -- 先声明变量在声明游标 declare u_name varchar(100); declare upro varchar(100); declare u_cursor cursorforselect name,profession from tb_user where age<=uage; declare exit handler fornot found close u_cursor; droptable if exists tb_user_pro; createtable if notexists tb_user_pro( id intprimary key auto_increment, name varchar(100), profession varchar(100) ); open u_cursor; while true do fetch u_cursor into u_name,upro; insertinto tb_user_pro values (null,u_name,upro); end while; close u_cursor;
CREATEFUNCTION 存储函数名称 ([ 参数列表 ]) RETURNS type [characteristic ...] BEGIN -- SQL语句 RETURN ...; END ;
characteristic说明:
DETERMINISTIC:相同的输入参数总是产生相同的结果
NO SQL :不包含 SQL 语句。
READS SQL DATA:包含读取数据的语句,但不包含写入数据的语句。
2). 案例
1 2 3 4 5 6 7 8 9 10 11 12 13
-- 从1到n的累加 dropfunction if exists fun1; createfunction fun1(n int) returnsintdeterministic begin declare total intdefault0; while n>0 do set total:=total+n; set n:=n-1; end while; return total; end; select fun1(100);